SPICE: Self-Play In Corpus Environments Improves Reasoning
An overview of our paper, SPICE (Self-Play In Corpus Environments). SPICE is the next step in our line of work on self-play for large language models, following SPIRAL. Where SPIRAL had a model sharpen its reasoning by playing a handful of fixed zero-sum games against itself, SPICE grounds the self-play loop in a far larger world: a single model plays a Challenger that mines a document corpus to pose grounded reasoning tasks, and a Reasoner that solves them without the document. Grounding in an external corpus removes the hallucination amplification and information symmetry that make closed-loop self-play plateau, and lets the model pose problems it could not have invented from its own weights alone, yielding consistent gains across mathematical (+8.9%) and general (+9.8%) reasoning.
Motivation: The Ceiling of Closed-Loop Self-Play
Reinforcement learning with verifiable rewards (RLVR) gave language models a dramatic boost in reasoning, from OpenAI o1
This is the thread we have been pulling. In SPIRAL
That question matters because self-play for language models keeps hitting a wall. Methods that let a model generate its own questions from scratch achieve a few initial gains and then plateau or collapse. Two failure modes recur:
- Hallucination amplification. When a model invents both the question and the gold answer with no external check, factual errors compound. The system trains on its own unverifiable fantasies.
- Information symmetry. When the problem generator and the solver share the same weights and the same knowledge, the generator cannot pose anything the solver does not already implicitly know. Challenge degenerates; the curriculum flattens.
More fundamentally, a closed-loop proposer never observes anything outside its own weights, so the set of problems it can pose is bounded by its own distribution, no matter how cleverly you decode. Even methods that work hard to keep synthetic data diverse stay bounded by their starting coverage, which is ultimately just a compressed snapshot of the original pretraining data
The lesson we took away: a self-improving system needs to interact with something outside itself. A closed loop can only recombine what it already holds. The question is what that “something” should be for a language agent.
Core Insight: A Corpus Is an Environment
The bet underneath SPICE is larger than the paper: that an agent should improve by interacting with the world to generate its own problems, a lifelong, goal-conditioned loop in which it observes something external and turns it into a goal to pursue. A document corpus is the most tractable stand-in for that world we can train on today. Web text is a compressed image of human knowledge, the most accessible microcosm of the world we have. By letting the model act on that corpus, sampling a document, extracting a verifiable answer, posing a question, SPICE turns a static dataset into an interactive environment. The Reasoner never sees the source document, so the Challenger can ground a question and its answer in content the Reasoner must genuinely reason to recover. Information flows from the world, through the Challenger, into challenges the Reasoner cannot shortcut.
This is not retrieval-augmented generation, though the surface mechanics rhyme. RAG fetches a document to answer a query; SPICE uses the document to manufacture a question and a checkable answer, then withholds it from the solver. Retrieval here is in service of generating problems, not solving them, and that asymmetry is the entire point. The mechanism also does not depend on the corpus being current: pointed at a live search index, the same Challenger could mine post-cutoff documents and pose problems the model cannot answer from memory. The corpus is simply the most convenient world to begin with.
This single move addresses both failure modes at once: document grounding anchors every question and answer in real content (no hallucination), and the asymmetry plus corpus diversity keeps the challenge alive (no symmetry collapse).
Research Questions
RQ2: Do the Challenger and Reasoner actually co-evolve, or does one outrun the other?
RQ3: Which ingredients (grounding, Challenger learning, reward shape, task format) actually matter?
RQ4: What does the emergent curriculum look like qualitatively?
The SPICE Framework
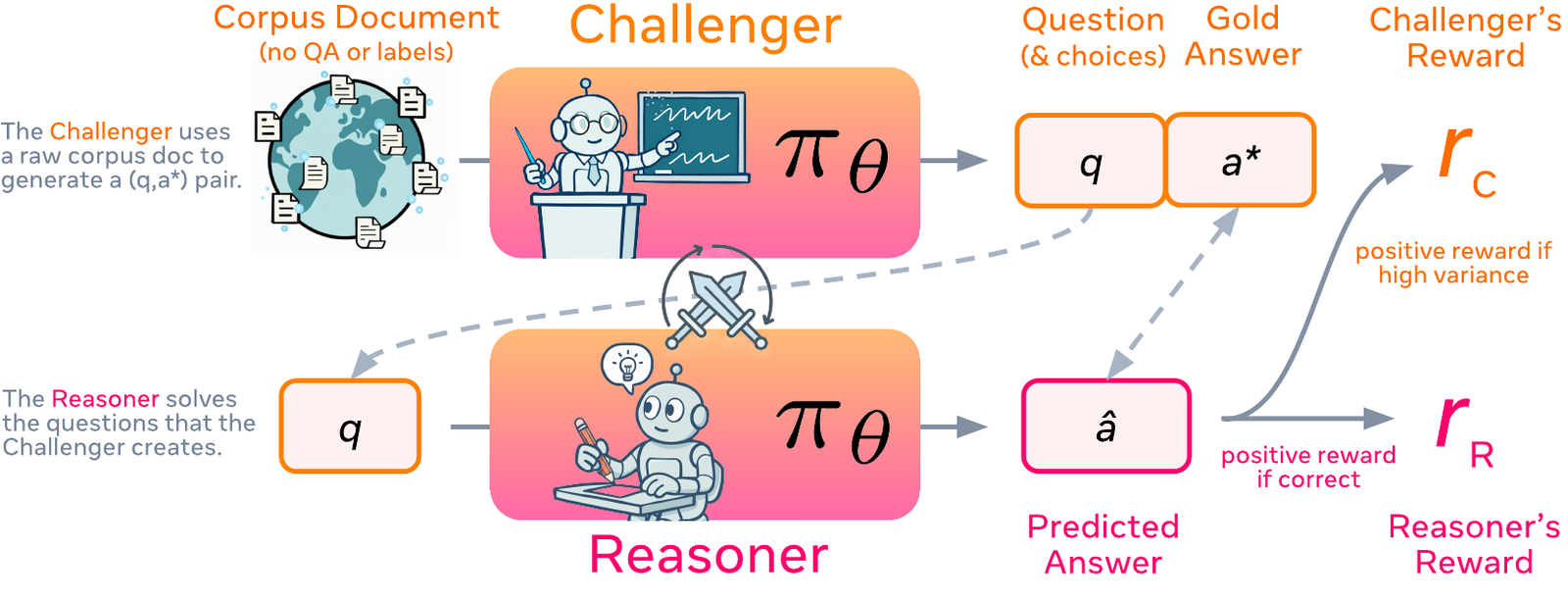
Challenger: Document-Grounded Task Generation
The Challenger uniformly samples a passage from the corpus (up to ~6K tokens), then takes multiple attempts to extract a verifiable task. It picks one of two formats based on the document: multiple-choice (four options, one document-grounded correct answer) or free-form with a typed answer (integer, expression, or string) extracted directly from the text. These typed formats act as universal verifiers, which is what frees SPICE from the executors and rule-based validators that confined prior self-play to math and code. The prompt walks the Challenger through multi-step information extraction, difficulty enhancement, and self-testing so questions are hard but still answerable without the source document.
Reasoner: Solving Without the Document
Given only the question, the Reasoner reasons step by step and boxes a final answer, relying purely on internalized knowledge. Its reward is binary correctness against the document-extracted gold answer, checked by a rule-based verifier (Math-Verify for expressions, exact match otherwise).
Variance-Based Curriculum Reward
The heart of the automatic curriculum is the Challenger’s reward. For each candidate question the Reasoner samples K answers (in our runs K = 8), and l_i = 1[â_i = a*] is the binary correctness of the i-th sample. The Challenger is rewarded by a Gaussian-shaped function of the variance of those correctness labels:
⎧ exp( −(Var(l_1..l_K) − 0.25)² / (2 · 0.01) ) if q is valid
r_C(q, a*) = ⎨
⎩ ρ otherwise (penalty)
For binary correctness, Var = p(1 − p) is maximized at p = 0.5, so the reward peaks exactly at a 50% pass rate (variance = 0.25). Questions that are too easy or too hard get exponentially less reward. As the Reasoner improves, the only way for the Challenger to stay rewarded is to pose harder questions, which is precisely the automatic curriculum. Both roles share weights and are trained jointly with DrGRPO Â_C = r_C − mean(r_C) and Â_R = r_R − mean(r_R)), centering each role on its own expectation so gradients reflect genuine learning signal rather than difficulty-induced noise.
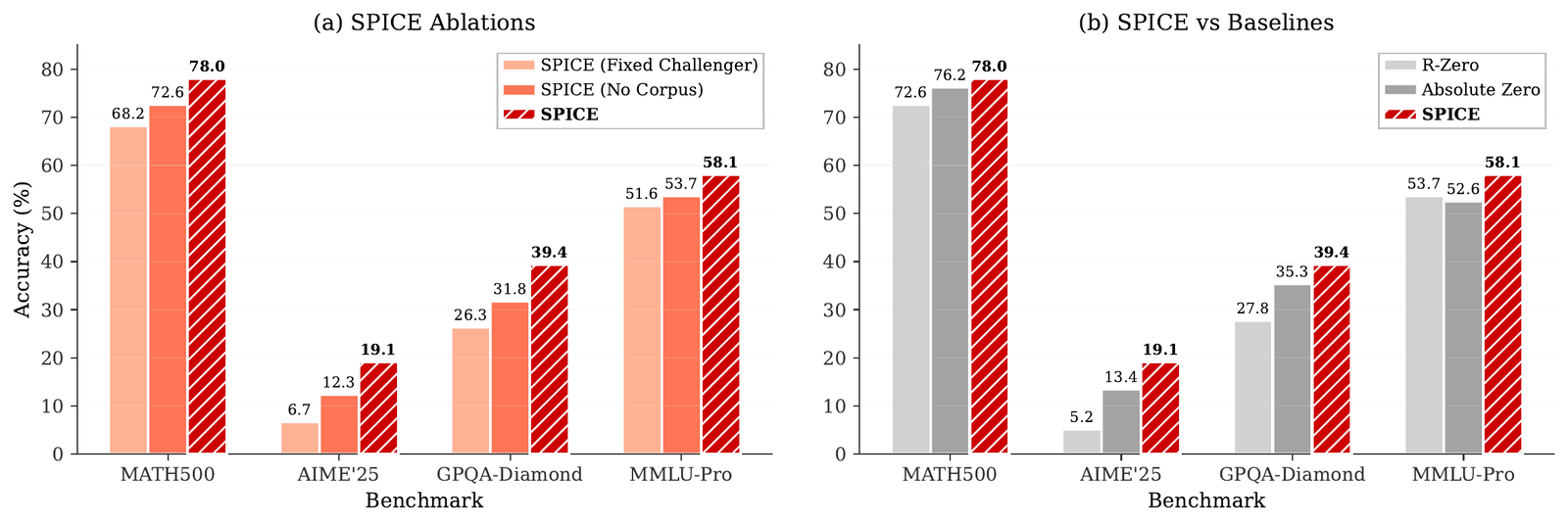
RQ1: Does corpus grounding beat ungrounded self-play?
We train on 20,000 documents (a 50/50 mix of Nemotron-CC-Math
| Base Model | Base | Strong Chal. | R-Zero | Absolute Zero | SPICE | Δ vs Base |
|---|---|---|---|---|---|---|
| Qwen3-4B-Base | 35.8 | 43.0 | 39.5 | 40.7 | 44.9 | +9.1 |
| Qwen3-8B-Base | 43.0 | 45.6 | 46.3 | 46.5 | 48.7 | +5.7 |
| OctoThinker-3B-Hybrid | 14.7 | 21.0 | 20.3 | 21.7 | 25.2 | +10.5 |
| OctoThinker-8B-Hybrid | 20.5 | 28.2 | 29.9 | 29.4 | 32.4 | +11.9 |
The pattern is robust: SPICE delivers the best overall accuracy on all four base models. Ungrounded self-play (R-Zero) gives among the smallest gains on the Qwen3-4B and OctoThinker-3B bases, and a fixed strong generator helps but cannot adapt to the Reasoner, while SPICE’s learned, grounded Challenger wins everywhere, with the largest headroom and the largest gap over baselines on the weaker OctoThinker bases.
RQ2: Do Challenger and Reasoner actually co-evolve?
A healthy self-play system needs both roles to climb together. We probe this by freezing one role at a step-200 checkpoint and sweeping the other across later checkpoints (steps 200-640) on a pool of 128 documents.
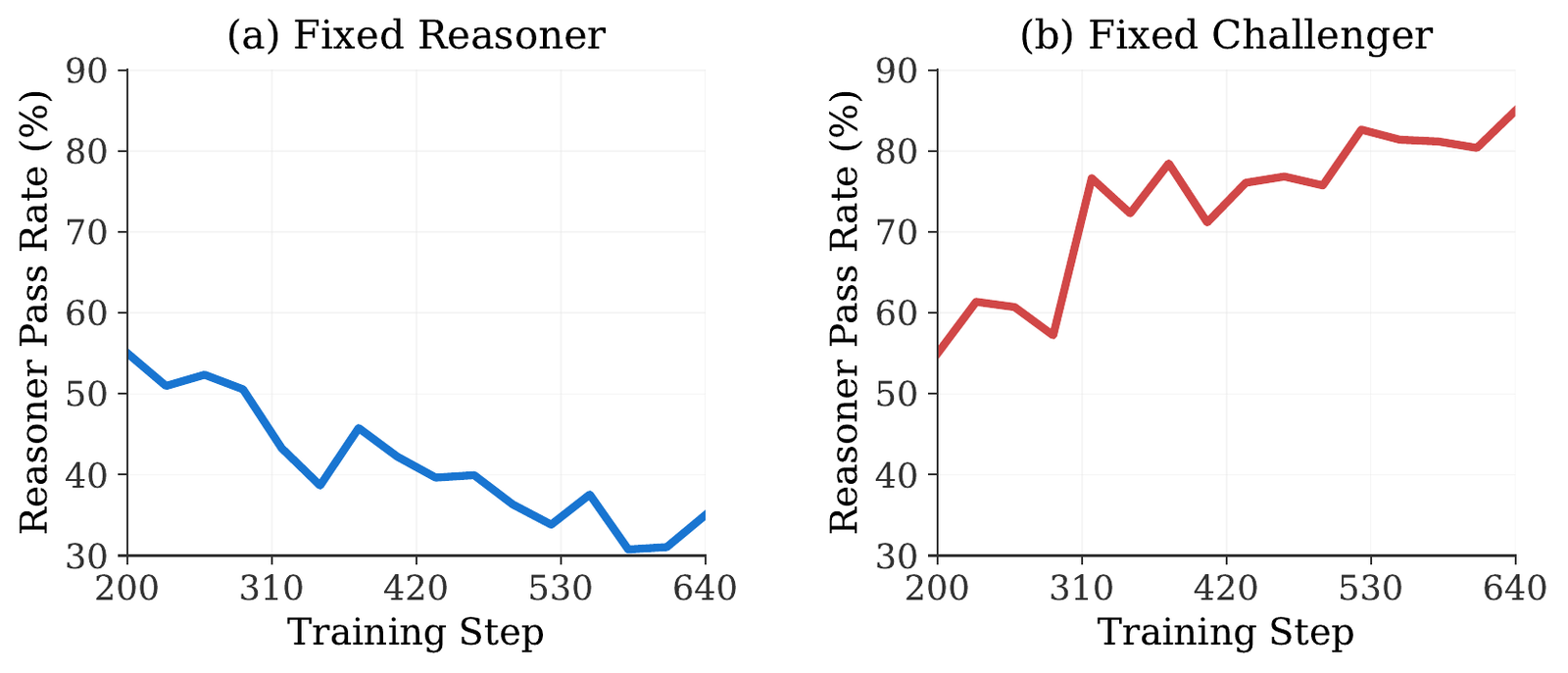
This is the signature of a working curriculum: each role improves monotonically against a fixed opponent, and neither saturates the other. That joint co-evolution actually beats training the Reasoner against a fixed Challenger is exactly what the ablation in the next section confirms.
RQ3: Which ingredients matter?
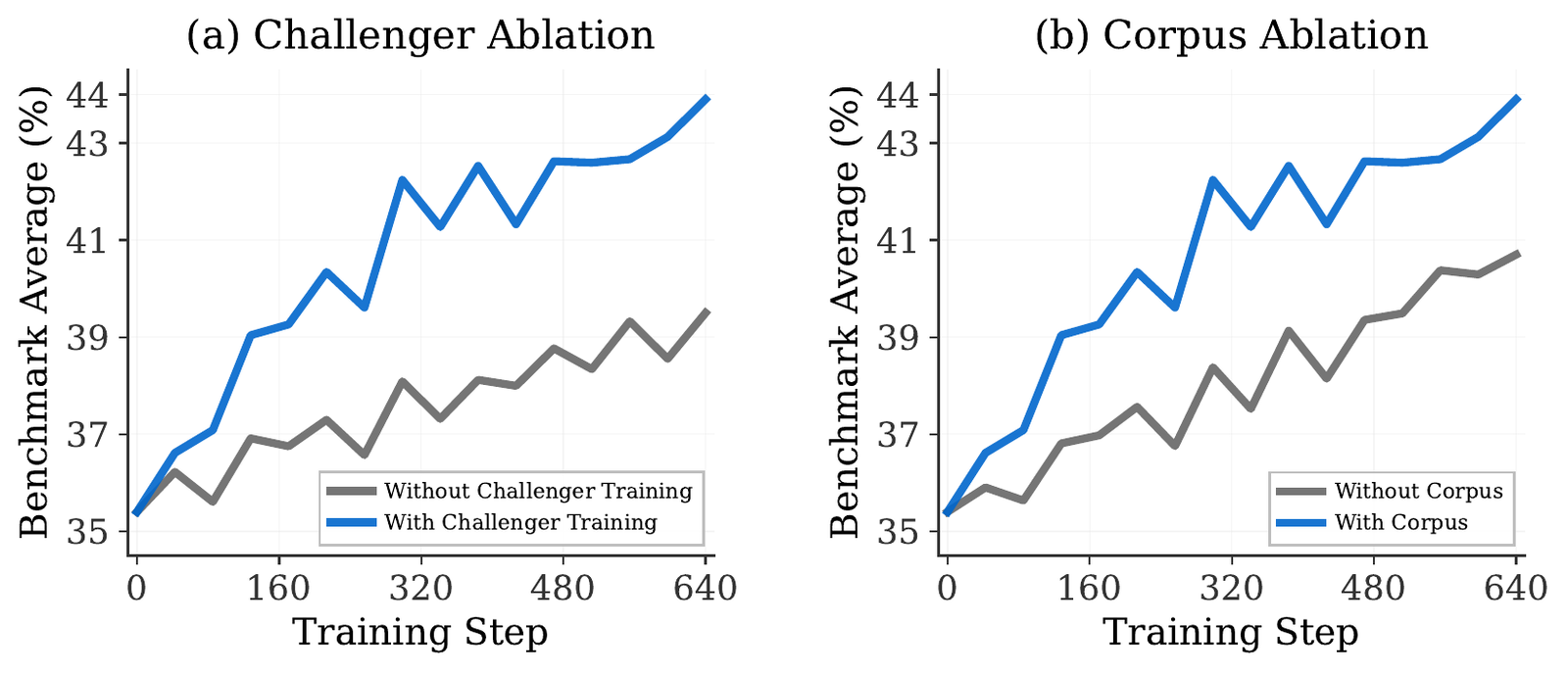
Three ablations pin down what is doing the work:
| Design choice | Variant | Overall |
|---|---|---|
| Corpus grounding | Without grounding | 40.7 |
| With grounding | 43.9 | |
| Challenger reward | Absolute Zero (1 − pass rate) | 40.7 |
| R-Zero (uncertainty) | 43.6 | |
| Variance (SPICE) | 44.9 | |
| Task format | MCQ only | 42.0 |
| Free-form only | 43.7 | |
| MCQ + free-form | 44.9 |
The reward result is the subtle one. Absolute Zero’s “harder is better” signal conflates difficulty with learning value; R-Zero’s uncertainty signal keys on agreement with a single mode; SPICE’s variance reward captures the full spread of the Reasoner’s answer distribution and peaks exactly where learning is richest, a balanced ~50% pass rate.
RQ4: What does the curriculum look like?
Given the same document at different training steps, the Challenger visibly escalates, from extracting an explicit fact to demanding multi-step proportional reasoning that still resolves to a document-stated value.
"What is the diameter of the Moon?" → B) 3,475 km
Late (step 480), multi-step reasoning:
"An alien moon of diameter 3,475 km creates perfect solar eclipses; its star has the Sun's diameter and the moon orbits at 374,000 km. Maintaining the same angular-size ratio, what is the planet-star distance?" → requires setting up Moon/Star angular-size equality, cross-multiplying, and matching to the document's value.
And the Reasoner escalates in lockstep, from an intuitive guess (“stars are ~1000× farther, so 374,000,000 km”) to a structured derivation: identify givens, write the angular-size equation, solve for the distance, then verify both angular sizes match. The curriculum produces authentic problem decomposition and self-correction, not memorization.
Where This Is Heading: From Corpus Grounding to Self-Generated Worlds
It is worth being precise about what SPICE buys and what it does not. It buys grounding, but it buys it from human experience: the goals the Challenger poses are still drawn from text that people wrote. A corpus is a microcosm of the world, not the world itself, and a model that only ever reads our documents is still, in the end, recombining our problems rather than discovering its own. The agenda that began with SPIRAL and continues through SPICE points past this: toward a model that generates experience of its own, not just reads ours.
Read as one arc, the trajectory is straightforward: self-play inside fixed games, then self-play grounded in a corpus, then environments the agent designs and grows for itself. Each step removes a different ceiling on open-ended self-improvement, and the corpus is the rung that converts a closed loop into one open to the world.
Conclusion
SPICE reframes self-improvement as interaction with an external corpus rather than closed-loop introspection. By splitting a single model into a document-grounded Challenger and a no-document Reasoner, and rewarding the Challenger for questions at the Reasoner’s frontier, SPICE:
- Beats ungrounded and domain-specific self-play across four base models, +9.1 / +5.7 / +10.5 / +11.9 overall, with broad transfer to both math (+8.9%) and general (+9.8%) reasoning.
- Sustains a genuine curriculum: Challenger and Reasoner co-evolve (fixed-Reasoner pass rate 55%→35%; fixed-Challenger 55%→85%) instead of collapsing.
- Isolates grounding as the load-bearing ingredient: removing the corpus drops performance from 43.9% to 40.7%, and the variance-based curriculum reward outperforms prior proposer rewards.
The takeaway is simple: closed-loop self-play runs out of road because a model cannot, by itself, be its own sufficient source of novelty and truth. We trained on only 20K documents and still saw no saturation, so the ceiling is the corpus, not the loop. Point the model at the world, even just the world’s text, and the loop opens back up.
In the spirit of the era of experience
Enjoy Reading This Article?
Here are some more articles you might like to read next:
- SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning
- TorchOpt: An Efficient Library for Differentiable Optimization