SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning
An overview of our paper, SPIRAL - Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning. In this paper, we introduce SPIRAL, a framework where self-play on zero-sum games incentivizes models to develop reasoning capabilities by automatically selecting generalizable Chain-of-Thought patterns from pretrained LLMs. This framework demonstrates that competitive game dynamics drive the discovery of reasoning strategies that transfer to mathematical and general reasoning benchmarks, serving as an initial exploration toward integrating self-play into the LLM self-improvement pipeline.
Motivation: The Scalability Crisis in Reasoning Enhancement
Recent breakthroughs in language model reasoning, including OpenAI o1
However, current RLVR approaches face a fundamental scalability bottleneck: their dependence on carefully engineered reward functions and domain-specific datasets

Self-play offers a solution to this scalability crisis by eliminating the need for human supervision in training data creation
Core Insight: Self-Play RL on Games Automatically Develops and Reinforces Increasingly Generalizable CoT Patterns
This insight builds on recent RLVR successes but removes their key limitation: human supervision. While RLVR requires experts to design rewards for each domain, games naturally provide clear feedback. The self-play mechanism is crucial: as models compete against themselves, they continuously raise the bar for what constitutes effective reasoning. Winning requires discovering CoT patterns that can’t be easily exploited, naturally selecting for strategies that generalize. As illustrated in the teaser figure above, this creates a fundamentally different paradigm where reasoning improvement emerges from competition rather than human design. The competitive pressure of zero-sum games ensures that only robust, generalizable reasoning strategies survive and get reinforced through training.
Research Questions
We investigate four key questions about self-play RL for reasoning enhancement:
RQ2: Does self-play's automatic curriculum outperform fixed-opponent training?
RQ3: Do different games develop specialized reasoning skills?
RQ4: Is Role-Conditioned Advantage Estimation (RAE) essential for stable self-play training?
RQ1: Can self-play on zero-sum games improve math and general reasoning capabilities?
Games as CoT Pattern Discovery Environments
Our first question tests whether competitive games alone can develop generalizable reasoning capabilities without domain-specific training data. We use three games that require distinct cognitive skills:
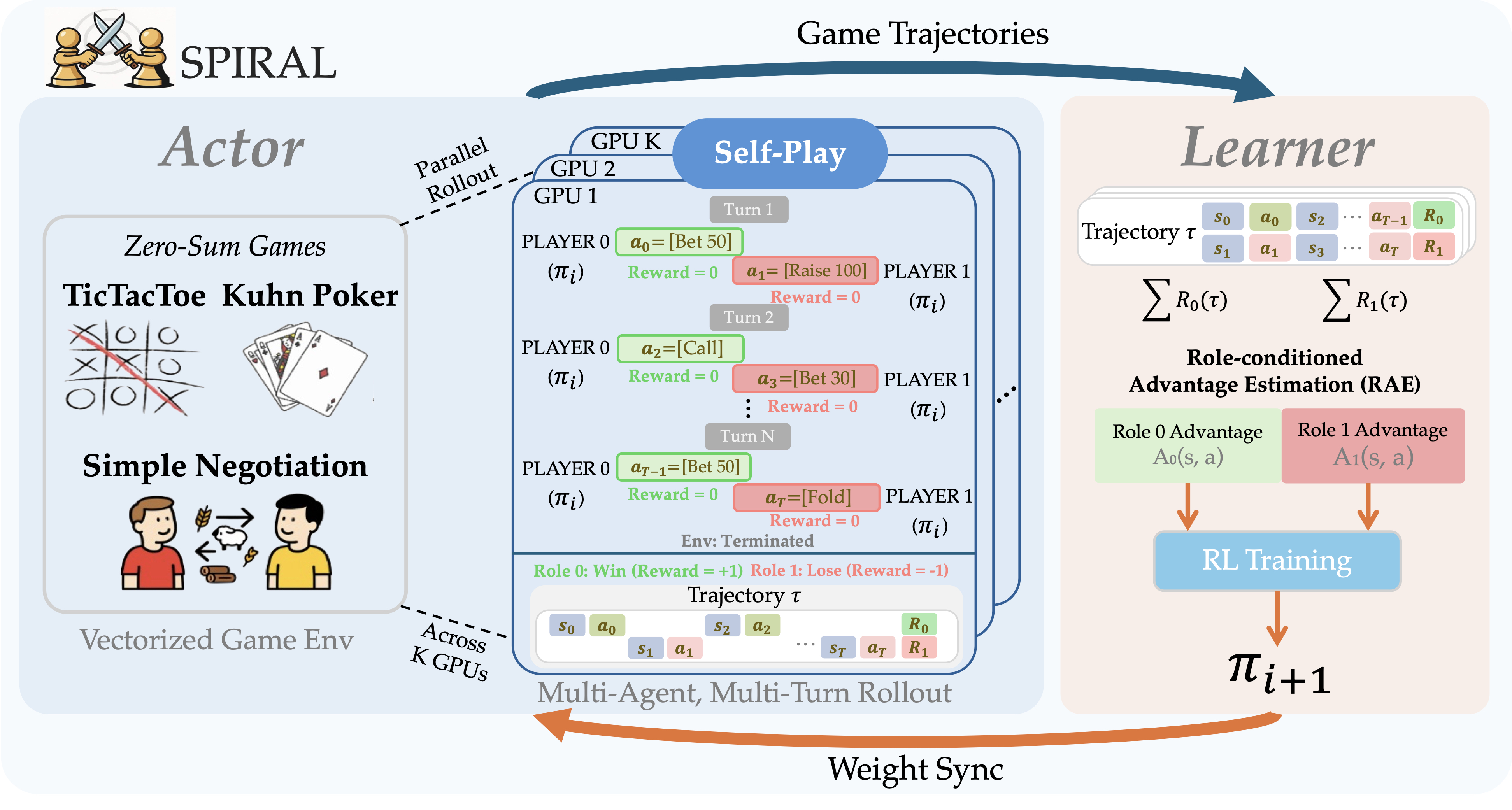
Requires pattern recognition and adversarial planning. CoT patterns must identify winning configurations and block threats.
Kuhn Poker (Probabilistic Reasoning):
Demands probability calculation and decision-making under uncertainty. CoT patterns compute expected values and model hidden information.
Simple Negotiation (Strategic Optimization):
Needs multi-step planning and theory of mind. CoT patterns must model opponent preferences and find mutually beneficial trades.
Three Generalizable CoT Patterns
Using GPT-4.1 to analyze thousands of game trajectories and math solutions, we discovered three core CoT patterns that emerge during gameplay and transfer to mathematics:
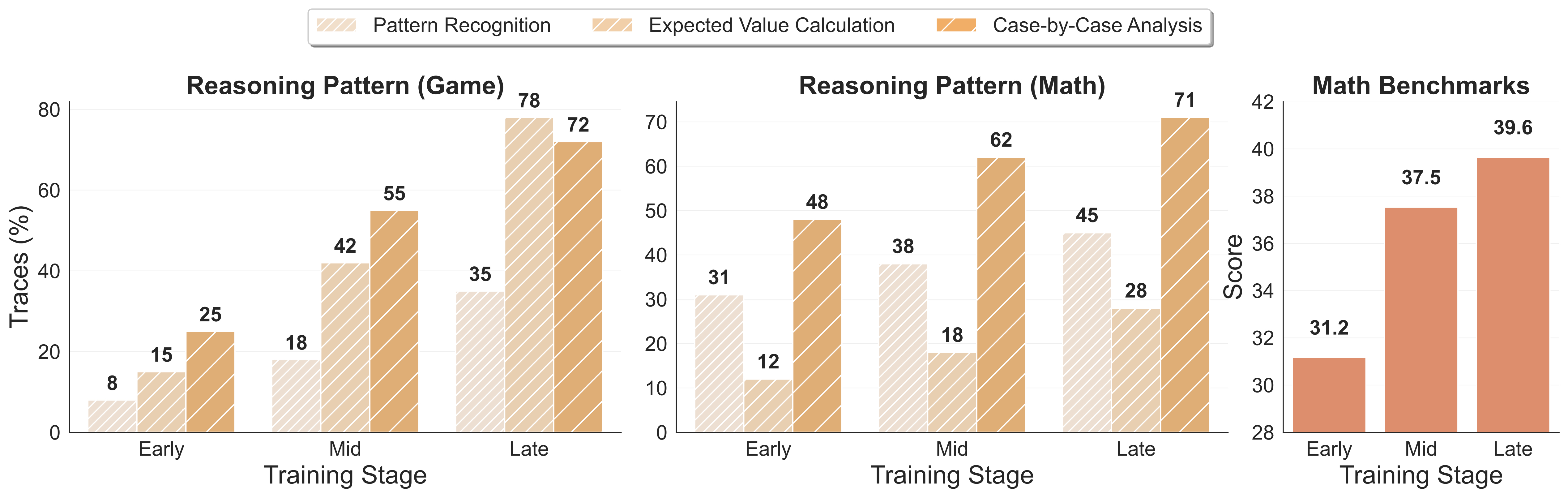
These patterns explain why training exclusively on Kuhn Poker improves mathematical reasoning by 8.6% and general reasoning by 8.4%, despite never seeing mathematical content. The competitive environment doesn’t just randomly improve reasoning; it systematically develops these three generalizable patterns that prove useful across domains.
RQ2: Does self-play’s automatic curriculum outperform fixed-opponent training?
Automatic Curriculum vs Static Training
Self-play promises infinite curriculum generation, but does this actually produce better learning than training against fixed opponents? We compare four training settings:
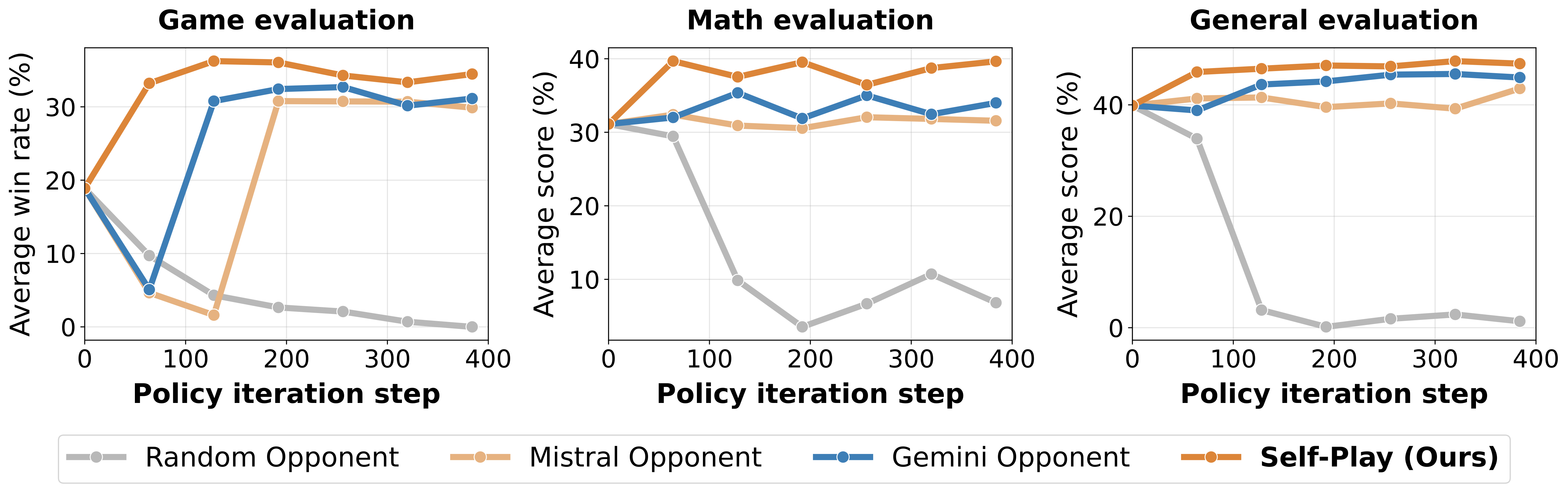
Avoiding Exploitation and Collapse
Two failure modes emerge in fixed-opponent training, as previewed in our teaser figure:
1. Curse of Turns in Format Learning: Random opponents cause complete collapse. The model must generate valid moves across entire trajectories to receive any reward, but the probability decreases exponentially with episode length.
2. Exploitation of Static Strategies: Fixed model opponents (Mistral, Gemini) enable format learning but lead to overfitting. Once the model finds winning counter-strategies, learning plateaus.
Self-play avoids both failures by continuously adjusting difficulty:
| Training Stage | Gemini Opponent Win Rate vs Gemini-2.0-Flash-Lite | Self-Play Win Rate vs Self (t-16) |
|---|---|---|
| Step 16 | 0.0% | 52.3% |
| Step 128 | 37.5% | 51.7% |
| Step 384 | 62.5% | 50.9% |
This balanced win rate confirms that the opponent evolves with the policy, maintaining consistent challenge throughout training.
RQ3: Do different games develop specialized reasoning skills?
Game-Specific CoT Patterns
We test whether distinct game mechanics cultivate different cognitive abilities by training specialists on each game and evaluating through head-to-head competition and out-of-distribution game transfer:
| Specialist Model | Win Rate on Own Game | Strongest OOD Game | Math Benchmark Avg |
|---|---|---|---|
| TicTacToe | 57.5% | Snake (56.0%) | +5.2% |
| Kuhn Poker | 64.2% | Pig Dice (91.7%) | +8.7% |
| Simple Negotiation | 62.7% | Truth & Deception (55.8%) | +4.8% |
Multi-Game Synergy
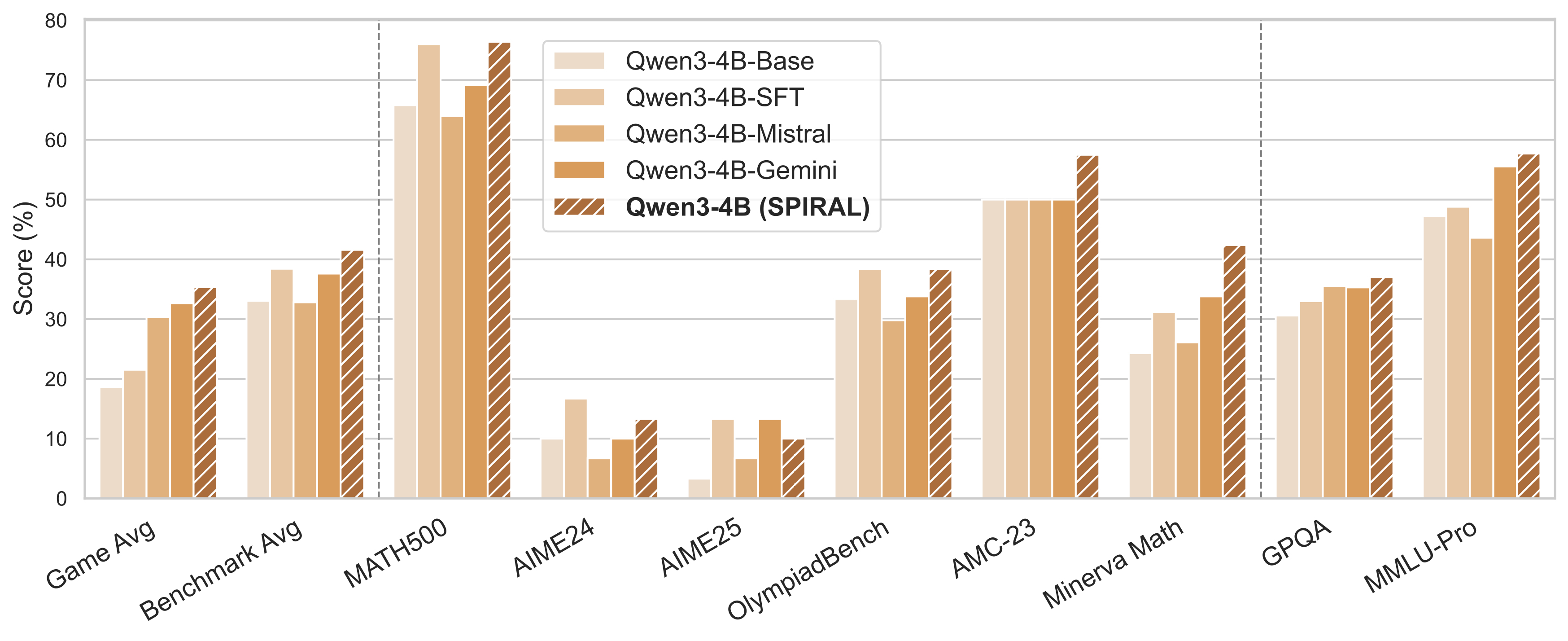
Training on multiple games creates synergistic benefits. The multi-game model achieves 44.9% average performance on out-of-distribution games, significantly outperforming any specialist (best: 34.4%). This confirms that diverse environments discover more generalizable CoT patterns.
| Model & Training | MATH500 | GPQA | MMLU-Pro | Average |
|---|---|---|---|---|
| Qwen3-4B-Base Family | ||||
| Base Model | 65.8% | 30.6% | 47.2% | 33.1% |
| + SFT (25K expert trajectories) | 76.0% | 33.0% | 48.8% | 38.4% |
| + SPIRAL (KuhnPoker only) | 76.4% | 37.0% | 56.5% | 41.4% |
| + SPIRAL (Multi-Game) | 74.2% | 36.9% | 57.7% | 42.3% |
| DeepSeek-Distill-Qwen-7B Family | ||||
| Base Model | 90.8% | 48.6% | 57.1% | 59.7% |
| + SPIRAL (Multi-Game) | 93.0% | 49.6% | 58.9% | 61.7% |
The results demonstrate that multi-game training creates more robust improvements than single-game specialists, and this benefit persists even for models that already excel at reasoning tasks. This suggests that competitive games develop complementary cognitive abilities not captured by traditional training approaches.
RQ4: Is Role-Conditioned Advantage Estimation (RAE) essential for stable self-play training?
The Thinking Collapse Problem
Training a single policy to play both sides of zero-sum games creates opposing objectives. Without proper variance reduction, this leads to catastrophic failure:
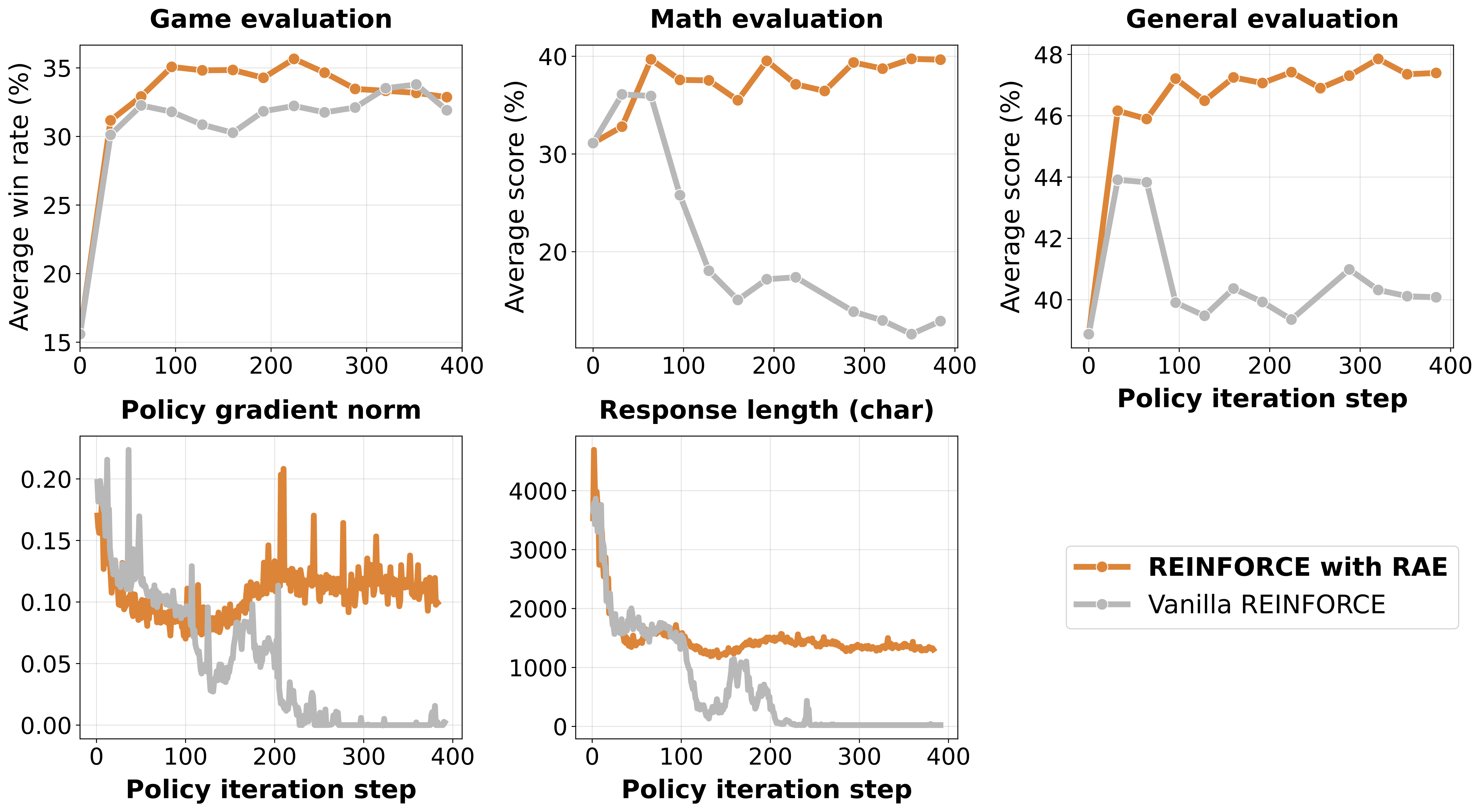
Role-Conditioned Advantage Estimation
RAE solves this by maintaining separate baselines for each role and game:
1
2
b_{G,p} ← α b_{G,p} + (1-α) R_p(τ) (update baseline)
A_{G,p}(τ) = R_p(τ) - b_{G,p} (compute advantage)
This accounts for role-specific asymmetries (e.g., first-move advantage in TicTacToe) and prevents the high-variance gradients that cause thinking collapse. With RAE, models maintain stable gradient norms around 0.1 and continue generating substantive CoT patterns throughout training.
Beyond Fixed Games: Self-Play with Adaptive Environments
Current limitations with fixed game environments:
- Human-designed games constrain the discovery space
- Static environments eventually saturate learning
- Limited diversity of reasoning challenges
The natural extension within the multi-agent framework is treating environment generation as another agent:
- Environment agent learns to generate problems that challenge current policy weaknesses
- Policy agent develops new CoT patterns to solve these adaptive challenges
- Maximized exploration where the policy encounters diverse environments tailored to its current capabilities, preventing overfitting to any fixed distribution
This multi-agent formulation with learnable environments could produce reasoning breakthroughs analogous to AlphaGo’s “move 37” - not just better performance on existing benchmarks, but fundamentally new approaches to problem-solving that emerge from the rich exploration enabled by adaptive environment generation.
Conclusion
SPIRAL demonstrates that self-play reinforcement learning can discover generalizable Chain-of-Thought patterns without human supervision. Our key findings:
-
Self-play on simple games improves reasoning - Kuhn Poker training alone achieves 8.7% average improvement on math benchmarks without seeing any mathematical content.
-
Automatic curriculum outperforms fixed training - Self-play avoids both format learning collapse and strategy exploitation through continuous adaptation.
-
Different games develop specialized CoT patterns - Each game environment selects for distinct reasoning skills that combine synergistically in multi-game training.
-
RAE prevents thinking collapse - Role-conditioned advantages are essential for maintaining stable CoT generation in self-play with shared parameters.
This work validates that RL can act as a discovery mechanism for the reasoning capabilities already latent in pretrained models. As we move toward multi-agent systems where environments and policies improve together through self-play dynamics, we may unlock reasoning abilities that no human could have designed or taught.
“We want AI agents that can discover like we can, not which contain what we have discovered.” - Richard Sutton
Enjoy Reading This Article?
Here are some more articles you might like to read next: